
TL;DR:
- AI now automates anomaly detection, event correlation, and remediation suggestions proactively.
- Progression through five maturity stages improves incident handling accuracy and autonomy over time.
- Effective AI integration relies on comprehensive telemetry, layered safeguards, and disciplined human oversight.
Most SREs still picture AI in incident response as a slightly smarter paging system. Alert fires, AI sends a Slack message, human scrambles. That mental model is years out of date. Today, AI automates anomaly detection, event correlation, root cause analysis, and remediation suggestions across complex cloud stacks, often before your on-call engineer has unlocked their laptop. This article breaks down exactly what AI handles now, how to integrate it with the tools you already run, where it still stumbles badly, and how to build a workflow that actually holds up under pressure.
Table of Contents
- AI in incident response: What has changed for SREs?
- Five maturity stages: How AI powers the modern incident response lifecycle
- Integrating AI with your cloud toolchain: Best practices and pitfalls
- Limits and risks: When AI can't replace SRE instincts
- From theory to practice: Key steps to leverage AI for efficient incident response
- Why AI alone won't fix incident response—and how to get the most from it
- Explore advanced AI solutions for your incident response needs
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| AI transforms incident response | AI enables rapid detection, analysis, and remediation far beyond basic automation. |
| Five-stage maturity model | Teams progress from basic anomaly detection to continuous learning with AI-driven incident handling. |
| Integrate with cloud tools | Connect AI systems to your existing cloud monitoring stack for the most meaningful impact. |
| Human oversight is crucial | SREs are still essential for handling ambiguous or novel incidents that AI cannot resolve. |
| Apply hybrid best practices | Combining AI efficiency with SRE expertise ensures effective and reliable incident response. |
AI in incident response: What has changed for SREs?
Not long ago, "AI-assisted incident response" meant threshold-based alerts with a fancy dashboard. Cross 80% CPU? Page someone. Simple. Painful. Slow.
That world is gone. Transforming incident response with AI now means systems that watch thousands of metrics simultaneously, spot subtle deviations before they become outages, correlate signals across services, and propose or execute fixes without waiting for a human to connect the dots.
The shift is significant. Here's what's actually different now:
- From threshold alerts to behavioral baselines. AI learns what "normal" looks like for your specific workloads, not just static numbers someone configured in 2022.
- From siloed alerts to correlated events. Instead of 40 separate alerts firing during a cascade failure, AI groups them into one coherent incident narrative.
- From manual RCA to automated diagnosis. The system traces the failure path through your dependency graph and surfaces a probable cause, often in under 60 seconds.
- From reactive runbooks to proactive suggestions. AI recommends or triggers remediation steps based on patterns from past incidents.
The benchmark has shifted too. Sub-minute incident diagnosis is now achievable for teams with mature telemetry pipelines. Understanding AI agent capabilities and pitfalls is essential before you build on this foundation. Speed without accuracy is just faster chaos. 😱
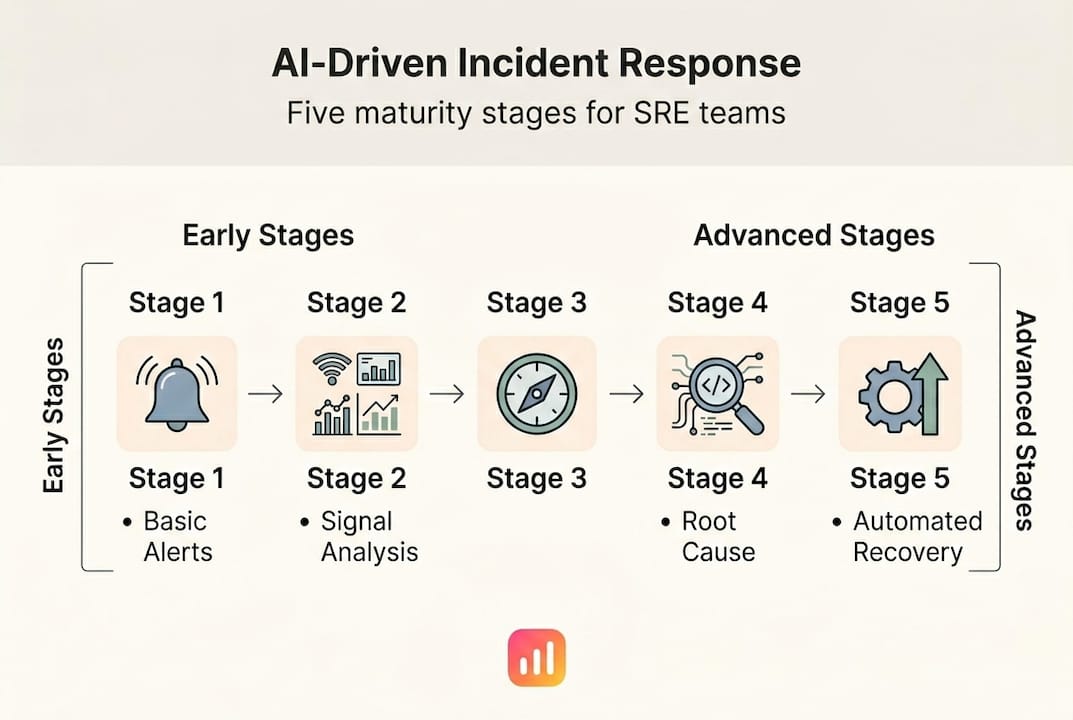
Five maturity stages: How AI powers the modern incident response lifecycle
AI doesn't arrive fully formed in your environment. It grows with your data quality and your team's confidence. The industry recognizes a five-stage maturity model that most teams move through progressively.
| Stage | Name | What AI does | Typical team readiness |
|---|---|---|---|
| 1 | Anomaly detection | Flags deviations from baseline | Early adopters, sparse telemetry |
| 2 | Alert correlation | Groups related signals into incidents | Moderate observability coverage |
| 3 | Action suggestion | Recommends runbook steps | Good data quality, some trust built |
| 4 | Controlled automation | Executes low-risk remediations autonomously | High telemetry fidelity, defined guardrails |
| 5 | Continuous learning | Improves from postmortems and feedback | Mature SRE culture, feedback loops embedded |
Here's how teams typically progress through these stages:
- Stage 1: Anomaly detection. Your AI watches Prometheus metrics and flags a memory leak pattern two hours before OOM kills your pods. No human spotted it. You start trusting the signal.
- Stage 2: Alert correlation. During a database failover, instead of 35 individual alerts flooding PagerDuty, AI surfaces one grouped incident with a dependency map. Your on-call says "finally."
- Stage 3: Action suggestion. AI reads the correlated incident, checks your runbook library, and suggests three remediation steps ranked by historical success rate. Your engineer picks one and executes.
- Stage 4: Controlled automation. For known issue patterns, like a specific pod crash loop with a proven restart fix, AI executes the remediation automatically within defined boundaries.
- Stage 5: Continuous learning. After each resolved incident, AI ingests your postmortem notes, updates its models, and gets measurably better at the next one.
Most teams land at Stage 2 or 3 within their first six months of a real AI-driven incident response rollout. Stage 5 is where the compounding returns begin.
Pro Tip: Don't rush to Stage 4. Premature automation without quality telemetry is how you get AI restarting the wrong service during a critical incident. Build trust through Stages 1 to 3 first, then expand autonomy carefully.
Integrating AI with your cloud toolchain: Best practices and pitfalls
Plugging AI into your existing stack is where theory meets reality. The good news: integrate AI with Kubernetes, Prometheus, CloudWatch and you unlock topology-aware correlation and root cause analysis with sub-minute diagnosis times. The bad news: most teams underestimate how much setup this actually requires.
Here are the major integration touchpoints and what you get from each:
| Platform | Integration depth | Key benefit | Common miss |
|---|---|---|---|
| Kubernetes | Deep (topology, events, pod logs) | Service dependency mapping, crash loop detection | Missing namespace-level RBAC for AI agents |
| Prometheus | Deep (metrics, PromQL, alerting rules) | Baseline modeling, anomaly scoring | Insufficient retention or scrape intervals |
| CloudWatch | Moderate (logs, metrics, alarms) | Cross-account AWS visibility | Not routing logs to central aggregator |
| Datadog | Moderate to deep (APM, traces, metrics) | End-to-end trace correlation | Missing trace sampling configuration |
| PagerDuty/OpsGenie | Surface (alerts, escalations) | Incident routing and suppression | Duplicate alert streams from multiple sources |
A few things consistently trip up even experienced teams:
- Incomplete telemetry coverage. AI correlation is only as good as the data flowing in. If 30% of your microservices have no tracing enabled, that's a 30% blind spot in your incident graph. Check your automated cloud monitoring strategies before assuming coverage is solid.
- Premature automation. Teams excited about Stage 4 automation enable it before their telemetry is reliable. AI then auto-remediates based on bad data. Ugly outcomes follow.
- Alert duplication loops. AI generates an alert, which triggers your existing alerting rules, which generates another AI notification. Without careful deduplication logic, your on-call drowns in noise instead of finding relief. Review your infrastructure monitoring tips to set up proper routing.
Pro Tip: Run a telemetry audit before any AI integration. Map every service to its observability coverage: metrics, logs, traces, and events. Fill gaps first. A two-week instrumentation sprint upfront saves months of debugging false AI signals later.
Limits and risks: When AI can't replace SRE instincts
Here's the part most vendors skip in their pitch decks. AI stumbles, sometimes badly, and your team needs to know exactly when.

Edge cases include novel failure modes, ambiguous signals, and confident wrong diagnoses that can trigger irreversible actions if you're not careful. The AI hasn't seen this failure before. It pattern-matches to the closest thing it knows. That nearest match might be completely wrong.
Three scenarios where AI consistently struggles:
1. Novel failure modes. Your cloud provider releases a new network feature that introduces a race condition in your service mesh. AI has zero training data on this specific interaction. It will either miss it entirely or misattribute it to something familiar. Your senior SRE who has seen weird network behavior before has a real edge here.
2. Ambiguous signals during multi-region failures. When a global CDN issue causes dozens of services to report degraded performance simultaneously, the signal is noisy and confusing. AI might chase a symptom while missing the actual cause upstream. Human judgment about blast radius and failure direction matters enormously in these moments.
3. Confident wrong diagnoses. This one is especially dangerous. AI pattern-matching fails on unseen incidents and the model may present an incorrect root cause with high confidence. Engineers who haven't been trained to question the AI's certainty can execute the wrong remediation and make things worse.
"The risk isn't that AI is wrong. It's that AI is confidently wrong in ways that look exactly like it's right. Your team needs override mechanisms and alternate hypotheses baked into the workflow, not as afterthoughts."
Safeguards that actually work:
- Tiered automation with human approval gates. Low-risk actions (pod restart, cache flush) can be automated. Anything touching databases, network configs, or load balancers requires explicit human sign-off.
- Mandatory alternate hypothesis generation. Before executing a remediation, require the AI to surface at least two alternative root causes. This forces the workflow to consider edge cases.
- Clear override paths. Every AI-suggested action needs a one-click override that any on-call engineer can trigger without going through bureaucracy.
- Feedback loops with postmortem integration. When AI was wrong, that data needs to feed back into the model. No feedback loop means the same mistake repeats.
- Time-boxed automation windows. Define hours or incident severity levels during which AI automation is active. Major incidents during peak traffic might warrant full human control.
From theory to practice: Key steps to leverage AI for efficient incident response
Understanding where AI shines and where it struggles is step one. Putting it to work is step two. AI excels at routine tasks and correlation but needs human-in-the-loop for high-risk actions and proper telemetry prerequisites. Here's how to build this out practically.
-
Prepare your data foundation first. Before touching any AI tooling, inventory your observability stack. Which services emit metrics to Prometheus? Which ship structured logs? Which have distributed tracing? Map coverage honestly. Fix instrumentation gaps on your top 20 most critical services before anything else. This step feels boring. It's also the one that determines whether everything else works.
-
Validate integrations with synthetic incidents. Once AI is connected to your stack, don't test it with real incidents. Create synthetic failure scenarios in staging: inject a pod OOM, simulate a database timeout, create a network partition. Observe how the AI correlates and diagnoses. Tune from there before going live.
-
Tier your automation by risk level. Work with your SRE team to categorize every remediation action into low, medium, and high risk. Low-risk actions get full automation. Medium-risk actions trigger AI suggestions with one-click human approval. High-risk actions always require manual execution. Document this tier list and revisit it quarterly. Check out best practices for multi-cloud automation for frameworks on categorizing risk across cloud environments.
-
Embed feedback loops from day one. Build a lightweight process where every resolved incident includes a quick AI accuracy check. Was the root cause diagnosis correct? Was the suggested remediation the right one? Capture this in your postmortem template. Feed disagreements back into your AI platform's training data or configuration. Teams that skip this step see AI accuracy plateau fast.
-
Layer human approvals into high-stakes moments. Build explicit checkpoints into your incident response workflow where human judgment is required before AI proceeds. These aren't bottlenecks. They're guardrails. An AI that can execute any action without a human approval path is an incident waiting to happen. Define these checkpoints in your runbooks and enforce them in your automation platform.
Why AI alone won't fix incident response—and how to get the most from it
Here's an opinion that might surprise you: the teams we see getting the most out of AI in incident response are not the ones with the most automation. They're the ones with the most disciplined humans.
Full automation is the dream. It's also often a trap. When something truly novel breaks, and it will, an over-automated system can mask the problem, apply wrong fixes confidently, and delay the moment a human realizes something is deeply wrong. We've seen this pattern repeatedly.
The teams that win treat AI as a copilot, not a pilot. The AI handles the first 80% of the cognitive load: spotting the anomaly, correlating the signals, surfacing the likely cause, suggesting the fix. The SRE handles the last 20% that actually requires judgment: is this diagnosis plausible given what I know about recent deployments? Does this remediation make sense given current traffic patterns?
What teams routinely overlook is postmortem integration. They use AI during the incident and then switch it off during the review. That's leaving the most valuable learning loop closed. Your postmortems contain exactly the edge cases, novel failure modes, and "AI was wrong" moments that should feed back into your AI system. Teams that feed postmortem data back consistently see compounding accuracy improvements over six to twelve months.
Another thing teams miss: cloud DevOps trends for 2026 point clearly toward hybrid intelligence as the dominant model. Not pure automation. Not pure human response. A disciplined combination where AI accelerates and humans verify. The teams building that muscle now will have a real operational advantage in the next wave of infrastructure complexity.
The uncomfortable truth is that AI surfaces your observability gaps faster than anything else. If your telemetry is incomplete, AI will make that very obvious, very quickly. Some teams find this uncomfortable. Smart teams treat it as a gift.
Explore advanced AI solutions for your incident response needs
You've now got a clear view of what AI can do, how to integrate it, where to be careful, and how to build it into your workflow step by step. The next move is finding tooling that meets the bar.

Argonix is built specifically for SRE and DevOps teams managing complex cloud environments. Our AI incident response platform connects AI agents to your existing stack through 40+ connectors, covering cloud providers, observability tools, CI/CD pipelines, and communication platforms. You get automated root cause analysis, tiered auto-remediation workflows, and local or cloud-based LLMs, keeping your data inside your own environment. Pair that with our infrastructure monitoring tools and GitOps automation solutions and you've got a complete operational intelligence layer that actually fits how modern cloud teams work.
Frequently asked questions
What are the main benefits of using AI for incident response?
AI enables faster detection, correlation, and remediation by automating anomaly detection, event correlation, root cause analysis, and remediation suggestions, cutting mean time to recovery significantly in cloud-native environments.
Does AI fully replace human SREs during incident response?
No. AI handles routine correlation and pattern matching well, but novel failure modes and ambiguous signals require human judgment, and SREs remain essential for high-stakes decisions and complex incident scenarios.
What are common pitfalls in AI-driven incident response?
The biggest pitfalls are over-trusting AI with incomplete telemetry data, skipping feedback loops, and lacking override paths. AI pattern-matching fails on unseen incidents without mechanisms for human correction built into the workflow.
How should teams start integrating AI with their current tools?
Start by connecting AI to your core monitoring stack. Integrating with Kubernetes, Prometheus, and CloudWatch gives you topology-aware correlation and root cause analysis with sub-minute diagnosis times for most common failure patterns.
#DevOps #SRE #IncidentResponse #CloudOps #AIAutomation #Argonix
Recommended
- Argonix | AI Ops Copilot - Monitoring, Incident Response & Infrastructure Automation
- Argonix | AI Ops Copilot - Monitoring, Incident Response & Infrastructure Automation
- Argonix | AI Ops Copilot - Monitoring, Incident Response & Infrastructure Automation
- Automate cloud monitoring: AI-driven efficiency in 5 steps